
2026年4月AI大模型排名:谷歌登頂,國(guó)產(chǎn)模型全面崛起
如果你最近還在用半年前選定的AI模型做業(yè)務(wù),可能要重新看一看了。
Artificial Analysis 每72小時(shí)更新一次的 LLM 排行榜,目前已收錄 317 個(gè)模型。這張榜單不是看論文發(fā)表數(shù)量,也不靠廠商自報(bào),而是從實(shí)際 API 調(diào)用中采集智能指數(shù)、響應(yīng)速度、成本和延遲這幾個(gè)維度的實(shí)測(cè)數(shù)據(jù)。換句話說(shuō),它大致反映了”花錢(qián)買(mǎi)到的模型到底怎么樣”。
智能指數(shù)前五,格局已經(jīng)變了
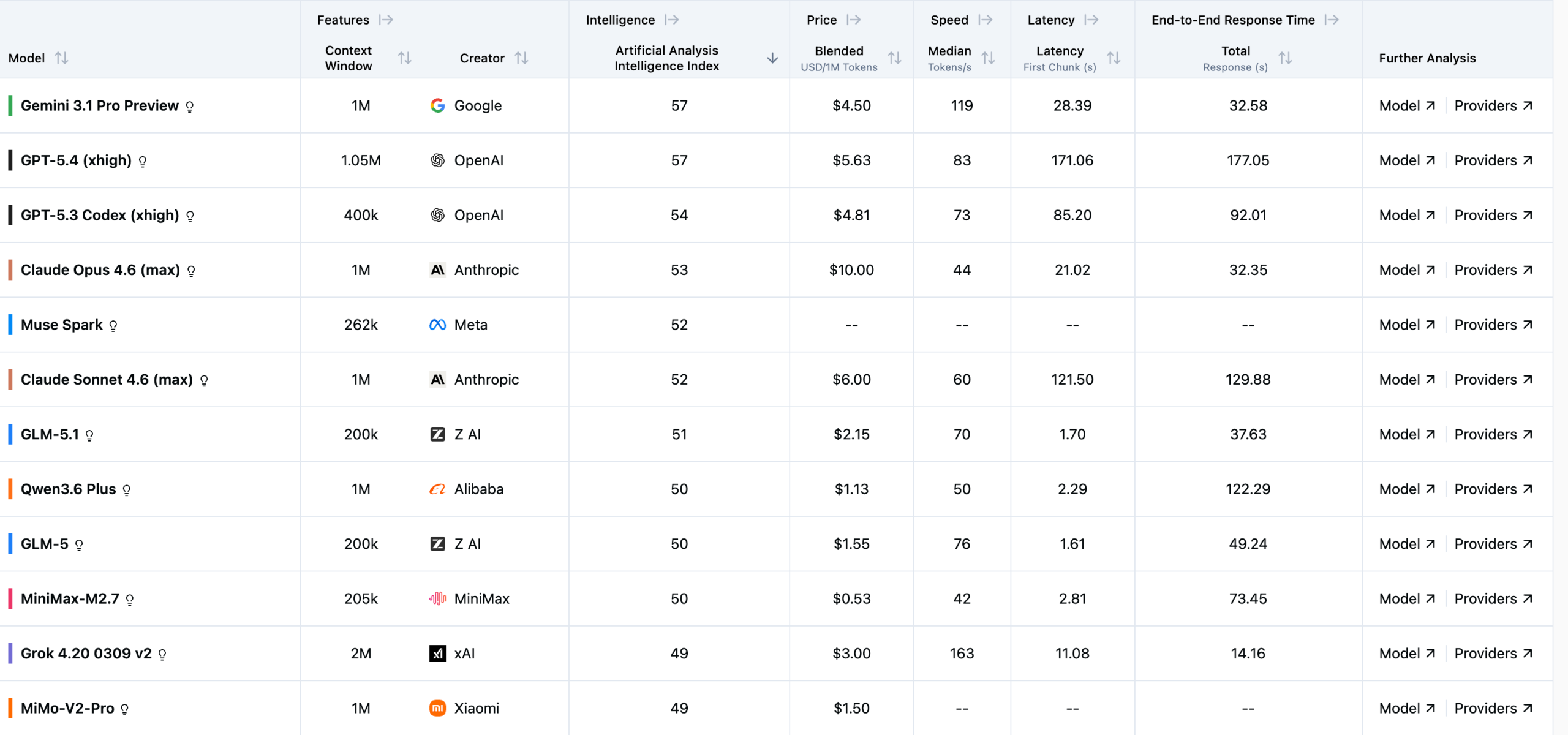
排行榜的核心是”智能指數(shù)(Intelligence Index)”,滿(mǎn)分不限,越高越好。截至2026年4月,前五名是:
Gemini 3.1 Pro Preview(谷歌,57分)和 GPT-5.4 xhigh(OpenAI,57分)并列第一,兩家打了個(gè)平手。第三是 GPT-5.3 Codex xhigh(OpenAI,54分),第四是 Claude Opus 4.6 max(Anthropic,53分),第五是 Meta 的 Muse Spark(52分)。
值得注意的是,谷歌這次是真正意義上的第一次登頂。過(guò)去幾年 GPT 系列幾乎是這類(lèi)榜單的常客,而 Gemini 3.1 Pro 以實(shí)測(cè)分?jǐn)?shù)追平 GPT-5.4,說(shuō)明谷歌在推理能力上已經(jīng)補(bǔ)上了短板。
Anthropic 的 Claude Opus 4.6 位居第四,但它的定價(jià)是每百萬(wàn) token 10 美元,在頭部模型里屬于偏貴的。Claude Sonnet 4.6 max 以52分緊隨其后,性?xún)r(jià)比稍好一些(6美元/百萬(wàn)token)。

速度榜:誰(shuí)響應(yīng)最快
如果說(shuō)智能指數(shù)是”聰不聰明”,那輸出速度決定的是”能不能用”。
目前最快的是 Inception 的 Mercury 2,實(shí)測(cè)達(dá)到 874 tokens/秒,遠(yuǎn)超其他模型。第二是 IBM 的 Granite 4.0 H Small(485 t/s),第三是 Granite 3.3 8B(375 t/s)。
這個(gè)速度意味著什么?普通閱讀速度大約是每秒4~5個(gè)漢字,一個(gè)874 t/s 的模型,用來(lái)做實(shí)時(shí)對(duì)話完全感覺(jué)不到等待。相比之下,Claude Opus 4.6 的速度是44 t/s,差了將近20倍,但它要解決的問(wèn)題類(lèi)型本來(lái)就不一樣。
延遲方面(首字符時(shí)間),阿里的 Qwen3.5 2B 和 Qwen3.5 0.8B 做到了最低延遲,非常適合需要快速響應(yīng)的實(shí)時(shí)場(chǎng)景。
最便宜的模型在哪里
價(jià)格維度,阿里的 Qwen3.5 0.8B 系列拿下了最便宜的席位,僅需 $0.02/百萬(wàn)token,基本等于白送。緊隨其后是 Google 的 Gemma 3n E4B($0.03)和 Qwen3.5 2B($0.04)。
DeepSeek V3.2 的價(jià)格是 $0.32/百萬(wàn)token,在同等智能指數(shù)水平(42分)的模型里屬于性?xún)r(jià)比極高的選擇。相比之下,OpenAI 的 GPT-5.4 Pro xhigh 要收 $67.5/百萬(wàn)token,算是榜單里最貴的,適合對(duì)精度要求極高、成本不敏感的場(chǎng)景。
開(kāi)源模型:國(guó)產(chǎn)已經(jīng)站上主力位置
榜單共有 196 個(gè)開(kāi)源(開(kāi)放權(quán)重)模型,占總數(shù)超過(guò)60%。
開(kāi)源模型排名第一的是 GLM-5.1,由智譜 AI(Z AI)發(fā)布,智能指數(shù)51分,收費(fèi)僅 $2.15/百萬(wàn)token。這是中國(guó)模型第一次在此類(lèi)國(guó)際榜單的開(kāi)源分類(lèi)中拿到第一。GLM-5(50分)緊接其后,Kimi K2.5 以47分位列第三。
除此之外,阿里的 Qwen 系列在這張榜單上幾乎占據(jù)了速度、價(jià)格、小尺寸模型的多個(gè)細(xì)分第一,出現(xiàn)頻率相當(dāng)高。國(guó)內(nèi)還有小米 MiMo-V2-Pro(49分)、DeepSeek V3.2(42分)、百度 ERNIE 5.0、字節(jié)跳動(dòng) Doubao Seed Code 等多個(gè)模型上榜。
一些值得關(guān)注的細(xì)節(jié)
首先是上下文窗口的分化。Meta 的 Llama 4 Scout 和 xAI 的 Grok 4.1 Fast 支持高達(dá) 1000萬(wàn) token 的上下文,而大多數(shù)模型在 128k~256k 之間。對(duì)于需要處理超長(zhǎng)文檔或代碼庫(kù)的應(yīng)用場(chǎng)景,這個(gè)差距會(huì)直接影響選型。
其次是推理模型(Reasoning Model)的比例越來(lái)越高,目前榜單上有159個(gè)推理模型,超過(guò)總數(shù)的一半。這類(lèi)模型在輸出前會(huì)進(jìn)行”思維鏈”擴(kuò)展,在數(shù)學(xué)、邏輯、代碼等任務(wù)上表現(xiàn)明顯更好,但同時(shí)延遲也更高——適不適合用,取決于業(yè)務(wù)場(chǎng)景對(duì)實(shí)時(shí)性的要求。
還有一個(gè)趨勢(shì)值得留意:越來(lái)越多的模型開(kāi)始追求”小而快”而不是”大而全”。Qwen3.5 0.8B、Ministral 3B、Phi-4 Mini 這些模型在特定任務(wù)上的表現(xiàn)已經(jīng)相當(dāng)可用,部署成本卻低出一個(gè)數(shù)量級(jí)。
怎么選模型
這張榜單的意義不是告訴你”用最貴的就行”,而是幫你找到你實(shí)際需求對(duì)應(yīng)的最優(yōu)解。
如果你要做復(fù)雜推理、深度研究,Gemini 3.1 Pro 或 GPT-5.4 是當(dāng)前上限。如果是日常對(duì)話、內(nèi)容生成類(lèi)的業(yè)務(wù),Claude Sonnet 4.6 或 DeepSeek V3.2 的性?xún)r(jià)比更好。如果對(duì)速度和成本都很敏感,Qwen3.5 系列幾乎是現(xiàn)在最省錢(qián)的選擇。
需要補(bǔ)充的是,智能指數(shù)反映的是綜合推理能力,并不等于”對(duì)你的業(yè)務(wù)有用”。具體任務(wù)還是要自己跑 benchmark,或者找專(zhuān)門(mén)的測(cè)評(píng)服務(wù)驗(yàn)證。榜單是參考,不是答案。
相關(guān)新聞
-
OpenClaw 能干什么?一個(gè)重度用戶(hù)的 10 個(gè)真實(shí)用例拆解
OpenClaw非常火爆非常強(qiáng)大,但它也很危險(xiǎn)!本文提供最基礎(chǔ)的場(chǎng)景介紹,看官按自己的承受能力選擇使用 近年來(lái),OpenClaw 龍蝦在國(guó)內(nèi)外的技術(shù)圈爆火,吸引了眾多關(guān)注。但與其大量的理論討論、架構(gòu)發(fā)展方向相比,真正的應(yīng)用場(chǎng)景卻少有人深入剖析。 那么,OpenClaw到底能為我們的日常工作提供哪些切實(shí)可行的功能呢?作為一個(gè)具備開(kāi)發(fā)能力的用戶(hù),我們通過(guò)一系列實(shí)際案例,展示了OpenClaw的多種應(yīng)用。通過(guò)這些用例,我們能更清晰地看到它如何影響和提升工作效率。 Clawd誕生于2025年11月——這…
-
各行業(yè)人工智能AI應(yīng)用案例:助力提升2??026年效率
在過(guò)去幾年里,人工智能已經(jīng)悄然成為眾多企業(yè)日常運(yùn)營(yíng)中不可或缺的一部分。它不再是科技公司專(zhuān)屬的前沿概念,而是切實(shí)改變著制造、金融、醫(yī)療、零售等傳統(tǒng)行業(yè)的運(yùn)轉(zhuǎn)方式。這場(chǎng)變革究竟走到了哪一步?企業(yè)在哪些場(chǎng)景中真正落地了AI應(yīng)用?本文嘗試從實(shí)際應(yīng)用出發(fā),梳理幾個(gè)最具代表性的領(lǐng)域。 一、從規(guī)則自動(dòng)化到智能判斷:一個(gè)根本性的轉(zhuǎn)變 傳統(tǒng)的自動(dòng)化工具能做的事情很有限——它們擅長(zhǎng)重復(fù)、固定的操作,一旦遇到例外情況或需要上下文理解的任務(wù),就會(huì)顯得力不從心。而近幾年興起的AI系統(tǒng)則不同,它們能夠從數(shù)據(jù)中學(xué)習(xí)規(guī)律,理解…
-
Nano Banana 2 技術(shù)解析:當(dāng)生成速度與專(zhuān)業(yè)畫(huà)質(zhì)不再需要二選一
2月26日,谷歌正式發(fā)布了?Nano Banana 2(Gemini 3.1 Flash Image)?。如果你是第一次接觸AI圖像生成,可能會(huì)被各種版本繞暈;但如果你是技術(shù)決策者,這次更新值得你花十分鐘重新評(píng)估——因?yàn)樗诟淖傾I生圖的單位經(jīng)濟(jì)模型。 產(chǎn)品定位變了:不是替代,是分層 先理清一個(gè)關(guān)鍵認(rèn)知:Nano Banana 2 并不是 Nano Banana Pro 的替代品,而是另一條產(chǎn)品線的能力補(bǔ)齊。 回顧一下時(shí)間線: 2025年8月:初代Nano Banana(Gemini 2.5 …
-
大廠的牛馬,也在被迫用AI
“被迫用AI”,這或許是2026年大廠員工最真實(shí)的寫(xiě)照。曾經(jīng)被視為提效神器的AI,如今正以一種復(fù)雜甚至矛盾的姿態(tài),深度嵌入我們的日常工作。它既是晉升的階梯,也是懸在頭頂?shù)倪_(dá)摩克利斯之劍。 01 Token與Skill:懸在頭頂?shù)男翶PI 在不少大廠,AI的使用早已從“鼓勵(lì)”變成了“強(qiáng)制”。你的績(jī)效,可能正與兩個(gè)新指標(biāo)緊密掛鉤:Token消耗量和Skill產(chǎn)出量。 1)Token消耗量:這成了衡量你是否積極擁抱AI的“硬通貨”。部門(mén)內(nèi)部甚至搭起了排行榜,誰(shuí)消耗的Token多,誰(shuí)的績(jī)效就可能更高。有…
-
AI人工智能體:人類(lèi)會(huì)因?yàn)閍i大面積失業(yè)嗎?
當(dāng)AI能完成你的工作,誰(shuí)來(lái)為你買(mǎi)單? 近年來(lái),人工智能技術(shù)以驚人的速度滲透到各行各業(yè)。從自動(dòng)駕駛汽車(chē)到智能客服,從醫(yī)療影像診斷到金融風(fēng)險(xiǎn)評(píng)估,AI正以前所未有的方式改變我們的工作生態(tài)。這種變革引發(fā)了一個(gè)緊迫的社會(huì)議題:人類(lèi)會(huì)因AI大面積失業(yè)嗎?本文將深入探討AI對(duì)就業(yè)市場(chǎng)的真實(shí)影響,分析哪些崗位面臨風(fēng)險(xiǎn),哪些機(jī)會(huì)正在涌現(xiàn)。 01 哪些工作最容易被AI取代? 不是所有工作都面臨同等風(fēng)險(xiǎn)。研究表明,具有以下特征的工作最易受影響: 1、高度重復(fù)性任務(wù):數(shù)據(jù)錄入、基礎(chǔ)客服、簡(jiǎn)單文書(shū)處理 2、模式識(shí)別類(lèi)工…
-
AI原生嵌入ERP:智能體+大模型正在改變企業(yè)管理系統(tǒng)的底層玩法
上個(gè)月跟一個(gè)做五金配件的老板聊天,他說(shuō)了句特別實(shí)在的話:”我花了兩百萬(wàn)上ERP,現(xiàn)在最大的感受就是——以前手工記錯(cuò)賬,現(xiàn)在系統(tǒng)里記錯(cuò)賬。” 他不是在否定ERP的價(jià)值。流程確實(shí)規(guī)范了,數(shù)據(jù)確實(shí)集中了。但業(yè)務(wù)員每天花大量時(shí)間在系統(tǒng)里錄單、翻菜單、跨模塊找數(shù)據(jù),干的全是”伺候系統(tǒng)”的活。ERP本來(lái)應(yīng)該是工具,結(jié)果活成了負(fù)擔(dān)。 這個(gè)問(wèn)題不是個(gè)例。很多企業(yè)的ERP系統(tǒng)用了五年八年,流程跑得通但效率上不去。不是系統(tǒng)不行,是它太”死”了—…
-
為什么ChatBI智能問(wèn)數(shù)是數(shù)據(jù)分析領(lǐng)域的下一個(gè)重大變革
傳統(tǒng)的商業(yè)智能工具,往往需要用戶(hù)先學(xué)習(xí)它的操作邏輯。你需要點(diǎn)擊菜單、設(shè)置篩選條件、選擇統(tǒng)計(jì)口徑,再等待儀表板加載完成。對(duì)于熟悉系統(tǒng)的人來(lái)說(shuō)這并不復(fù)雜,但對(duì)于大多數(shù)業(yè)務(wù)人員而言,門(mén)檻并不低。 對(duì)話式商業(yè)智能改變了這種使用方式。它不是讓人去適應(yīng)系統(tǒng),而是讓系統(tǒng)理解人的提問(wèn)方式。比如直接輸入“哪些客戶(hù)群體流失風(fēng)險(xiǎn)最高”,系統(tǒng)就會(huì)自動(dòng)在數(shù)據(jù)庫(kù)中查找相關(guān)數(shù)據(jù),并返回結(jié)果。整個(gè)過(guò)程更接近日常交流,而不是技術(shù)操作。 這種變化帶來(lái)的影響,不只是操作更方便。更重要的是,它改變了數(shù)據(jù)的使用范圍。過(guò)去很多數(shù)據(jù)查詢(xún)需要…
-
AI Agent 到底是怎么干活的?一文弄懂AI Agent完整工作流程
想象一下,你告訴AI:“幫我策劃一個(gè)下周末去杭州的兩天一夜旅行,預(yù)算2000元,要包含高鐵票和一家評(píng)分4.5以上的酒店,然后把行程發(fā)到我的郵箱。” 如果是在幾年前,你可能會(huì)得到一個(gè)包含各種鏈接和文字建議的回復(fù)。但今天,一個(gè)真正的AI Agent(智能體)會(huì)怎么做? 它會(huì)像一個(gè)經(jīng)驗(yàn)豐富的私人助理一樣,默默地開(kāi)始工作:查詢(xún)下周末的高鐵班次、比較價(jià)格和余票;搜索杭州的酒店,并根據(jù)你的預(yù)算和評(píng)分要求進(jìn)行篩選;將選定的交通和住宿信息整合成一個(gè)清晰的行程表;最后,將這個(gè)行程表打包發(fā)送到你指定的郵箱。 這一切…
-
企業(yè)合同與客戶(hù)信用風(fēng)險(xiǎn)管理系統(tǒng):打造信用驅(qū)動(dòng)的合同全生命周期風(fēng)控平臺(tái)
企業(yè)合同和客戶(hù)信用風(fēng)險(xiǎn)管理系統(tǒng)是為企業(yè)中高級(jí)管理人員和業(yè)務(wù)管理部門(mén)建立的綜合風(fēng)險(xiǎn)控制平臺(tái)。系統(tǒng)圍繞“客戶(hù)信用”的核心變量,開(kāi)放合同管理、收款控制、人員證書(shū)合規(guī)管理和風(fēng)險(xiǎn)預(yù)警中心,構(gòu)建可追溯、可控、可預(yù)警的數(shù)字風(fēng)險(xiǎn)管理系統(tǒng)。 系統(tǒng)的主要功能包括: 合同全生命周期管理,包括合同的起草、審核、簽訂、暫停、終止、續(xù)訂等 客戶(hù)信用驅(qū)動(dòng)型收款策略控制,每個(gè)客戶(hù)都有自己的信用度,信用度會(huì)隨著合同的執(zhí)行情況變化調(diào)整 人員與證書(shū)合規(guī)管理,自動(dòng)合規(guī)驗(yàn)證和證書(shū)生命周期管理 統(tǒng)一風(fēng)險(xiǎn)預(yù)警中心 人工智能協(xié)助條款風(fēng)險(xiǎn)識(shí)別與…
-
認(rèn)證機(jī)構(gòu)設(shè)備銘牌自動(dòng)識(shí)別案例
一、行業(yè)痛點(diǎn) 設(shè)備銘牌信息的收集和輸入是檢測(cè)、備案、維護(hù)的重要環(huán)節(jié),是檢測(cè)機(jī)構(gòu)日常業(yè)務(wù)中的重要環(huán)節(jié)。但是,在傳統(tǒng)的方式下,這一環(huán)節(jié)普遍存在以下痛點(diǎn): 手工錄入效率低、易出錯(cuò) 工作人員需要逐一拍照、記錄紙張或手動(dòng)輸入設(shè)備型號(hào)、編號(hào)、制造商、生產(chǎn)日期等銘牌信息。,而且流程繁瑣,數(shù)據(jù)容易漏填或錯(cuò)填。 數(shù)據(jù)標(biāo)準(zhǔn)不統(tǒng)一、信息孤島 不同人員的輸入格式不同,數(shù)據(jù)難以結(jié)構(gòu)化,后期難以系統(tǒng)管理,導(dǎo)致信息跟蹤困難,統(tǒng)計(jì)分析有限。 現(xiàn)場(chǎng)環(huán)境復(fù)雜,采集不便 檢測(cè)現(xiàn)場(chǎng)條件復(fù)雜,如光線不足、空間狹小,導(dǎo)致照片模糊或銘牌內(nèi)容…
